
语音识别技术,目标是以电脑自动将人类的语音内容转换为相应的文字。语音识别技术的应用包括语音拨号、语音导航、室内设备控制、语音文档检索、简单的听写数据录入等。
那么,这里我们使用python基于Sphinx来实现离线语音识别
模块安装
首先我们使用pip安装SpeechRecognition和PocketSphinx模块:
1 | pip install SpeechRecognition |
安装报错的解决方案
在PocketSphinx模块的安装过程中,可能会出现如下错误:
1 | error: command 'swig.exe' failed: No such file or directory |
这里写得很明确,我们缺少swig.exe。
因此,我们下载swig (windows版本):
链接: https://share.weiyun.com/MBfG4d9r (密码:4oFA)
下载后解压到任意目录,然后在Path环境变量中添加此目录(根据你的实际路径添加)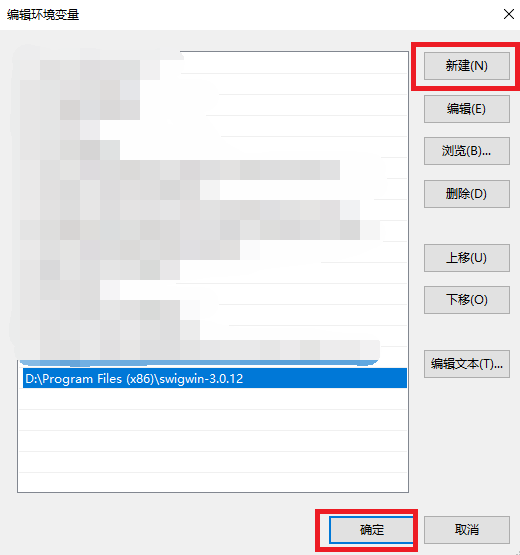
然后确定即可。
再次执行PocketSphinx模块安装命令(如果之前打开了命令窗口需要关闭后重新打开,环境变量才能生效),
就能成功安装了:
1 | Successfully built PocketSphinx |
语音识别
实现例子的代码如下(这样只支持英语识别):
1 | import speech_recognition as sr |
我们将一段名为test.wav的录音,放在py程序的同目录下。
运行程序,即可输出识别结果。
注:SpeechRecognition支持语音文件类型如下:
- WAV: 必须是 PCM/LPCM 格式
- AIFF
- AIFF-C
- FLAC: 必须是初始 FLAC 格式;OGG-FLAC 格式不可用
如果出现以下错误,说明你的PocketSphinx模块未正确安装:
1 | Sphinx error; missing PocketSphinx module: ensure that PocketSphinx is set up correctly. |
其它语言的识别
如要支持其它语言的语音识别,需要下载语音包,点此查看
下载速度可能较慢,这里提供中文普通话的语音包:
链接: https://share.weiyun.com/vzkwg487 (密码:5TvI)
下载完成后解压,找到python的安装目录,进入Lib\site-packages\speech_recognition\pocketsphinx-data目录。
可以看到里面只有一个”en-US”文件夹,我们新建一个名为”zh-CN”的文件夹,将刚才解压的语音包移动到里面。
然后将zh_cn.cd_cont_5000文件夹重命名为acoustic-model,zh_cn.lm.bin命名为language-model.lm.bin,zh_cn.dic命名为pronounciation-dictionary.dict: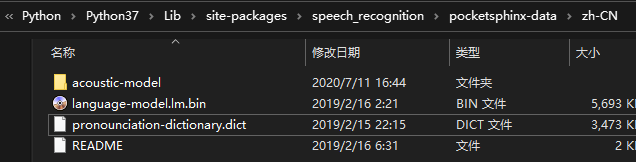
随后我们即可进行中文普通话语音识别,将上述代码进行微改:
1 | import speech_recognition as sr |
除此之外,其它语言也是类似的。
实际上,此语音识别识别率并不高,毕竟是简易的离线语音识别。
调用麦克风录音并识别
调用麦克风需要安装pyaudio模块:
1 | pip install pyaudio |
如果你安装过程中出现如下错误,可能是因为你的python版本为3.7 (pip安装的pyaudio不支持3.7,3.7以上版本未知):
1 | "portaudio.h":No such file or directory |
解决方案为:从https://www.lfd.uci.edu/~gohlke/pythonlibs/#pyaudio 下载你需要的版本,如python3.7 64位就选cp37,amd64那个。
下载完后,使用pip进行本地安装:
1 | pip install 你下载的whl路径 |
即可完成安装。
我们这里拿第一个示例稍作修改,代码如下:
1 | import speech_recognition as sr |
运行程序,当我们说一段话并停止,就会自动进行语音识别。
至此,我们便完成了简单的离线语音识别。
